
Quizás no es correcto empezar esta entrada con un «como todos ya sabéis», porque no es una noticia que haya saltado a los medios generalistas, pero a poco que estéis un poco pendientes del mundillo tecnológico recordaréis que un centro de datos de la empresa francesa OVH ardió en la madrugada del 10 de marzo de 2021 en Estrasburgo. Atando cabos sueltos como esta información y el título de esta entrada probablemente caeréis en que esta web que estáis visitando ahora tuvo «algo» que ver con ese evento.
Y efectivamente. Ésta fue una de esas webs alojadas en la nube de OVH que ardió durante esa noche intentando hacer realidad eso de la nube. Aunque eso sí, en este caso más que una nube de vapor de agua era una nube de humo, resultado de la combustión de diferentes elementos como madera, plástico, ciertos metales y cualquier otro material de los que un centro de datos esté hecho. Amigos, seamos realistas, «la nube» no existe, y es, simplemente, el ordenador de otro. En este caso, «el otro» es simplemente alguien que no tuvo la previsión o los medios necesarios para combatir un incendio.
Lloros aparte, la realidad es que durante la mañana del 10 de marzo, algunos de los que comprobamos que nuestro servidor no estaba accesible vimos el siguiente tweet del CEO de OVH y se nos pusieron, por decirlo finamente, «los pelos de punta».

Lo primero que te viene a la mente es: ¿Qué narices es eso de un plan de recuperación de desastres? ¿Se come? En mi caso particular lo que he perdido es solamente un blog, pero, siendo realistas, hay numerosas empresas y tiendas online que se han quedado sin un montonazo de datos. Pero no, este pequeño blog no tenía ningún plan de recuperación ante desastres y lo único que pude hacer es levantar una copia de la última vez que migré el servidor a un VPS nuevo (el que ahora está quemado) allá por 2018.
Esta copia, afortunadamente, la pude guardar a buen recaudo en un disco duro de mi casa y contenía toda la base de datos completa y toda la carpeta de WordPress. Gracias a ella pude levantar en pocas horas un sitio web análogo y evitar así que los enlaces se convirtieran en un 404 para Google, lo que habría supuesto una auténtica ruina en términos de SEO.
Sin embargo, como habréis adivinado, octubre de 2018 es casi tres años antes a la fecha del incendio de estrasburgo. Eso quiere decir que todo lo que se publicó y ocurrió en ese lapso de tiempo está fundido. Reconozco que el Wayback Machine de Internet Archive ha sido la herramienta indispensable que me ha permitido recuperar algunas de esas entradas. Poco a poco iré recuperando algunas de esas que se perdieron, aunque no son determinantes en cuestión de SEO, apenas tenía alguna visita.
Pero, miremos al futuro, ¿no? ¿Qué podemos hacer para que esto no me vuelva a pasar? Porque seamos claros, lo que ayer fue un incendio, mañana podría ser un terremoto, una inundación u, ojalá que no, un ataque terrorista. Y cuando nos pidan «oye, activa tu plan de recuperación de desastres», daremos un paso al frente y diremos «Por supuesto, lo tengo».
Creando nuestra estrategia de backup
Quiero avisar, lo primero, de que esto es algo totalmente amateur, y que lo que aquí comento vale para alguna cosa que tengas privada y la quieras mantener, pero si de verdad quieres tener una estrategia más «seria», lo mejor es que contactes con alguien con muchos más conocimientos y experiencia.
Dicho esto, cuando hables con alguien sobre hacer copias de seguridad, seguramente te mencionará eso de «la regla 3-2-1″. Esto quiere decir: «Mantén tres copias de seguridad de tus archivos, de las cuales, dos de ellas en medios diferentes y una de ellas fuera del lugar habitual».
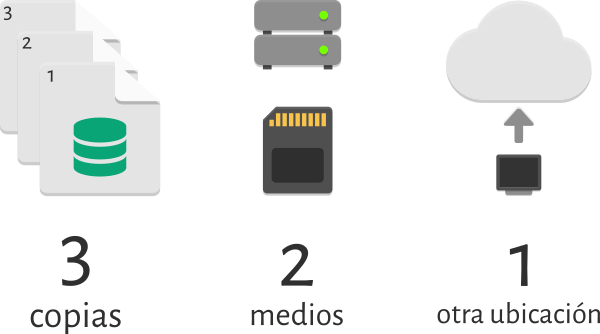
Contada la teoría, pasemos a la práctica. Y la primera pregunta que nos surge, o al menos a mí (que al fin y al cabo es el que paga el alojamiento de este blog mes a mes) es, ¿y esto cuánto cuesta? Ya de entrada os digo que si no contraté el backup con OVH fue porque me costaba prácticamente lo mismo al mes que lo que ya pagaba por el VPS (alrededor de 3€ sin IVA). Por lo que se hace urgente buscar otra solución.
Cuando de almacenar archivos se trata, a cualquiera que haya tocado temas de proveedores cloud, lo primero que le viene a la mente es sin duda el concepto de «object storage». Éste ha venido siendo implementado principalmente por AWS como S3 (Simple Storage Service), aunque otros proveedores lo han implementado con Swift, perteneciente al ecosistema de Openstack. Proveedores como… ¡OVH! Veenga, ¿qué probabilidades hay de que te toque la lotería dos veces? Hay otros proveedores con soluciones interesantes, como Scaleway o Exoscale, que merecerá la pena investigar, sobre todo por el precio que ambos ofrecen: alrededor de 1 céntimo el GB.
Por el momento yo implementaré una estrategia parcial, que consistirá en tener una carpeta local duplicada con las carpetas que queramos conservar dentro del VPS (esto facilitaría la recuperación en caso de borrado accidental y permitiría hacer una simple copia de los archivos rápidamente) y otra copia externa, usando el servicio de Cloud de OVH. Prometo mejorar en el futuro y usar otro servicio, pero de momento esto es lo que hay…
Acceso al Object Storage de OVH Cloud
La configuración del almacenamiento se puede hacer desde la interfaz de cliente de OVH. Necesitarás crear un proyecto nuevo si no tienes uno, y después, un object storage en una región que elijas. Para evitar tocar mucho los tokens y APIs, lo que vamos a hacer es crear un usuario de OpenStack para usarlo con nuestras copias de seguridad. Esto se hace fácilmente dentro de nuestro panel del proyecto, en «Project Management > Users and Roles». Ahí le daremos a añadir usuario y seleccionaremos la opción de «ObjectStorage Operator».
Ahora necesitaremos crear un archivo openrc.sh para poder conectarnos desde nuestro servidor a la infraestructura de Openstack. Para hacerlo simplemente pulsaremos en el botón de opciones del usuario que acabamos de crear y pedimos descargar un archivo RC de Openstack. Esto nos guardará en nuestro ordenador un script bash que lo usaremos posteriormente para autenticarnos.
Sólo nos faltaría una última cosa: La ruta del bucket que hemos generado. Esta es fácil de obtener, al abrir el bucket en la interfaz de cliente la veremos directamente allí. Ahora vamos a meter las manos en la masa y ver cómo implementamos nuestro backup.
Uso del cliente Swift
Ahora queda instalar el cliente en nuestro VPS. Asumiré que corre con Ubuntu 20.04, si es una versión posterior no debería cambiar mucho lo que hagamos, y si es otro sistema operativo probablemente cambie el nombre del paquete, pero poco más. El cliente Swift se puede instalar así:
sudo apt-get install python3-swiftclient
Con esto ya tendremos disponible el comando swift en nuestro sistema. Sin embargo nos faltará todavía autenticarnos. Tendremos que usar el archivo openrc para configurar unas variables cada vez que vayamos a usar el comando swift (o cualquier otro comando de Openstack, en realidad). Copiadlo al servidor y vamos a hacerle una pequeña modificación para poder automatizarlo todo en un script:

El script está pensado para usarse en una línea de comandos interactiva, pero no es lo que buscamos. Para ello cambiamos esa pequeña parte del script hasta dejarlo como vemos en la imagen. Es decir, comentamos las líneas que solicitan la contraseña y a cambio configuramos manualmente la variable OS_PASSWORD. Guardamos el archivo y lo cerramos. Recomiendo crear una carpeta en /opt para ir guardando todos estos scripts que estamos generando.
Ahora con sólo ejecutar el siguiente comando ya estaremos autenticados. Nos vamos a la carpeta donde lo hayamos guardado y escribimos en la terminal:
source openrc.sh
Y podremos ejecutar comandos de swift. Todos tienen una estructura en común:
swift subcommand [bucket [archivo]]
Podemos ejecutarlo con el subcomando «list» para ver los buckets disponibles que tenemos.
swift list
Nota: si vemos que nos da error, recomiendo esperar unos minutos y volver a probar. Puede que todavía se esté sincronizando la contraseña/tokens/etc. entre todas las zonas del cluster openstack de OVH.
El resto de subcomandos que nos interesan son upload y probablemente también delete para borrar objetos antiguos. Pero bueno, la verdad es que lo interesante será automatizar todo esto en un script. Para facilitar un poco el proceso de escribirlo, como ya lo he tenido que hacer yo una vez, lo he subido a gitlab con la esperanza de que sea útil a alguien.
Este script permite automatizar todo el proceso así como configurar que los objetos de backup creados tengan una fecha determinada de expiración, que nos facilitará mucho la gestión de copias de seguridad antiguas. Lo he incluido en la versión final del script, que lo podemos descargar con un sólo comando de esta forma y nos lo instalará directamente en la carpeta /opt:
sudo wget https://gitlab.com/-/snippets/2093368/raw/master/backup_and_upload.sh -O /opt/backup_and_upload.sh
Ahora sólo tendremos que editarlo para cambiar todo lo que necesitemos. Puedes cambiar el editor nano por emacs o vim. Las variables que tenéis que editar sí o sí están marcadas con un TODO. El resto lo podéis modificar si os gusta más de una forma u otra.
sudo nano /opt/backup_and_upload.sh
Y una vez editado el archivo, sólo nos queda probarlo. Vamos a darle permisos de ejecución antes, con
sudo chmod +x /opt/backup_and_upload.sh
Y ahora para ejecutarlo sólo tendremos que hacer un
sudo /opt/backup_and_upload.sh
Si todo ha salido como debería, ahora en la interfaz de cliente de OVH, al abrir los buckets, deberíamos poder ver nuestro archivo subido. ¡Eso quiere decir que nos ha funcionado! Y sólo nos quedaría hacer una última cosa.
Automatizando nuestra copia de seguridad
Sólo nos queda una última cosa, que a mi parecer es clave para que nuestro backup «triunfe». Y no es ni más ni menos que ejecutar este script periódicamente sin tener que estar pendientes de hacer nada. Para ello vamos a añadir una sentencia al cron de root. Para abrirlo hacemos simplemente un:
sudo crontab -e
Y añadimos una línea al final del archivo:
0 3 * * * /opt/backup_and_upload.sh >> "/opt/log_backup_and_upload.log"Guardamos y salimos. Esta sentencia nos permitirá correr el backup a las 3:00 de la mañana todos los días. Para ver si funciona nos tocará esperarnos al día siguiente. Pero con todo esto nos tendremos asegurada una política de backup, que, quizás algo parcial, pero mejor que antes seguro que sí.
¡Un saludo!
Pingback: Uso de IBM Object Storage en Nextcloud | Cambia de SO